
Blog Article
HTTP通信の仕組みについて
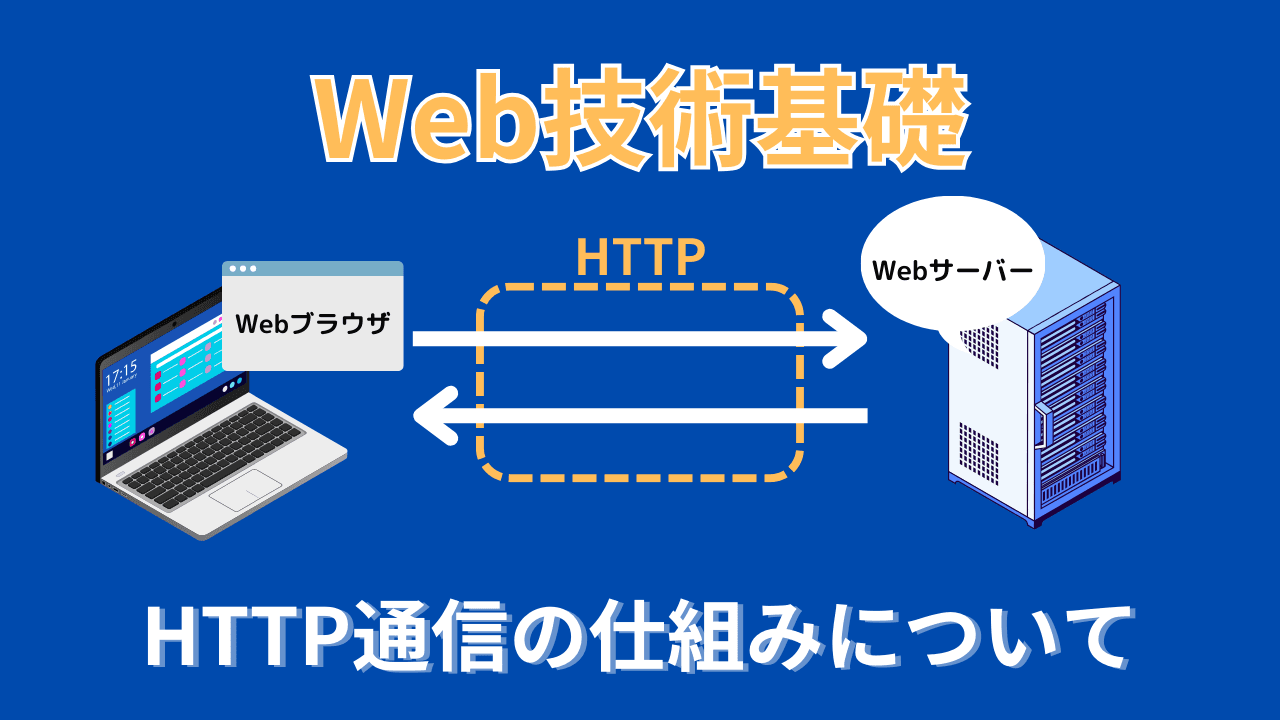
HTTPとは
HTTPは、インターネット上でデータをやり取りするルールを決めた仕組み (プロトコル) です。簡単に言えば、ウェブページや画像などの情報をクライアント (ブラウザ) とサーバー間で送受信するための手順です。
HTTPの基本ポイント
- リクエストとレスポンスの仕組み
- クライアント (例: ブラウザ)がリクエストを送信します。
例: 「このページを見たい!」 - サーバーがそのリクエストに応じてレスポンスを返します。
例: 「ページのデータをどうぞ!」
イメージ:
- あなた (クライアント) がレストランで注文 (リクエスト)
- 店員 (サーバー) が料理を提供 (レスポンス)
- クライアント (例: ブラウザ)がリクエストを送信します。
- ステートレス (状態を覚えない)
HTTPでは、1回のリクエストとレスポンスが完結します。サーバーは「前回何を頼んだか」を覚えていません。
例: ブラウザがページを開くたびに、新しいリクエストが送信されます。注意: ユーザーの状態 (ログインなど) を覚えさせるためには、クッキーやセッションなどの仕組みを追加で使います。
- テキスト形式でやり取り
HTTPの通信はテキストで書かれており、人間が読める形になっています。
ブラウザが「index.html」というページを要求する命令の例 ↓
例: 「GET /index.html HTTP/1.1」
- 暗号化されない (非安全)
HTTPは通信を暗号化しません。送ったデータがそのまま外部に見えるリスクがあります。
HTTPS (HTTP Secure) を使えば暗号化され、安全に通信できます。
- ポート番号80
通常、HTTP通信はポート80を使用します。
URLにポート番号を書かない場合でも自動的に80が使われます。
- 拡張性が高い
HTTPには、ヘッダーという追加情報を送る仕組みがあります。
例: ユーザーのブラウザ情報や言語設定を伝えるます。また、新しい機能を後から追加しやすいプロトコルです。
まとめ
HTTPは、ウェブページや画像などを取得する基本的な仕組みです。ただし、暗号化がないためセキュリティに弱く、現在では多くのサイトがHTTPS (暗号化されたHTTP) を使っています。
覚えやすいポイント
- リクエスト (要求) → レスポンス (返答)
- 状態を覚えない (ステートレス)
- HTTPはそのままだとセキュリティが弱い → HTTPSが推奨!
分かりやすく言うと、HTTPは「情報を取りに行くためのルールブック」です。
HTTPSとは
HTTPSは、インターネット上のデータ通信を暗号化して安全にする仕組みです。簡単に言えば、通常のHTTP通信に「鍵をかける」ことで、第三者にデータを盗み見られないようにしています。
HTTPSの基本ポイント
- 通信の暗号化
- 通信データを暗号化して、他の人が内容を読めないようにします。
- たとえば、クレジットカード情報やパスワードを送るときも、暗号化されていれば安心です。
イメージ:
手紙の内容を読まれないように、特別な鍵で封をするようなもの。
- 公開鍵と秘密鍵の仕組み
- サーバーは「公開鍵」と「秘密鍵」のペアを持っています。
- 公開鍵: 誰でも使える鍵 (暗号化に使う)
- 秘密鍵: サーバーだけが持つ鍵 (復号に使う)
例:
公開鍵を使ってデータを暗号化すると、秘密鍵を持つサーバーだけがその内容を解読できます。
- サーバーは「公開鍵」と「秘密鍵」のペアを持っています。
- SSL/TLSハンドシェイク
- HTTPS通信を始める前に、クライアント (ブラウザ) とサーバーの間で「通信を安全にする準備」をします。
- このやり取りを「ハンドシェイク」と呼びます。
流れ:
- クライアントがサーバーに「証明書」をくださいとリクエスト。
- サーバーが公開鍵と証明書を渡します。
- クライアントがその証明書を確認し、安全な暗号化方法を決定。
- その後、暗号化された通信が始まります。
- SSL証明書 (証明書の役割)
- サーバーが信頼できることを証明するものです。
- 証明書には、サーバーの公開鍵や運営者情報が含まれており、「認証局 (CA) 」という機関が発行します。
例:
証明書があれば、偽サイトではなく本物のサイトと通信していると確認できます。
- セキュリティ向上の理由
- データの盗聴防止: 第三者が通信内容を盗み見ても解読できません。
- データ改ざん防止: データが途中で改ざんされていないことを確認できます。
- 正当性の保証: サイトが本物であることを証明します。
HTTPSが重要な理由
- パスワードやクレジットカード情報を送信する際に、情報漏洩を防ぐため。
- 信頼性の証明 (ブラウザに「鍵マーク」が表示され、安心感を与える)
- 検索エンジンでも、HTTPSサイトが優遇されることが多い。
まとめ
HTTPSは、データを暗号化して盗み見や改ざんを防ぎ、信頼性を保証する仕組みです。
特に個人情報や機密データを扱う場合、HTTPSは必須の技術です。
ポイント ↓
- データに「鍵」をかける (暗号化)
- 「本物のサイト」と確認する仕組み (証明書)
- 安全なやり取りをする準備 (ハンドシェイク)
HTTPメッセージ
HTTPメッセージは、クライアント (例: ブラウザ) と サーバー がやり取りするデータの形式を指します。このやり取りには、HTTPリクエスト (クライアントからの要求) と HTTPレスポンス (サーバーからの返答) の2種類があります。
HTTPリクエストの構造
- リクエストライン
- リクエストの概要が書かれている。
- 例:
GET /index.html HTTP/1.1- メソッド:
GET(リソースを取得したい) - パス:
/index.html(取得したいリソースの場所) - HTTPバージョン:
HTTP/1.1
- メソッド:
- ヘッダー
- 追加情報を送る部分。
キー: 値形式。Host: www.example.com User-Agent: Mozilla/5.0- Host: サーバーのドメイン名。
- User-Agent: クライアント (例: ブラウザ) の情報。
- 追加情報を送る部分。
- 空行
ヘッダーと本文 (ボディ) の区切り。
- ボディ (本文)
- 必要なデータを送る場所。
- 例:
name=John&age=30(フォームデータなど)
HTTPレスポンスの構造
- ステータスライン
- サーバーがリクエストをどう処理したかの結果。
- 例:
HTTP/1.1 200 OK- HTTPバージョン:
HTTP/1.1 - ステータスコード:
200(成功) - 状態テキスト:
OK(成功の説明)
- HTTPバージョン:
- ヘッダー
- 追加情報を返す部分。
キー: 値形式。Content-Type: text/html Content-Length: 1234- Content-Type: 本文のデータ形式 (例: HTML、JSON)
- Content-Length: 本文のサイズ (バイト数)
- 追加情報を返す部分。
- 空行
ヘッダーと本文の区切り。
- ボディ (本文)
- 実際のデータ。
<html> <body>Hello, World!</body> </html>
- 実際のデータ。
HTTPメッセージのやり取り例
- クライアントがリクエストを送信
GET /index.html HTTP/1.1 Host: www.example.com User-Agent: Mozilla/5.0 - サーバーがレスポンスを返す
HTTP/1.1 200 OK Content-Type: text/html Content-Length: 123 <html> <body>Hello, World!</body> </html>
これがHTTPメッセージの基本構造です。リクエストでは「何をしてほしいか」を伝え、レスポンスでは「結果はこうなったよ」を返します。
HTTPメソッド
HTTPメソッドは、Webブラウザ (クライアント) とWebサーバーが通信する際に、クライアントがサーバーに対してどのような操作を要求するかを指定するための手段です。
GETメソッド
- 用途: サーバーからデータを取得する際に使用します。
- 例: Webページの表示、画像や動画の取得など。
- 特徴: データの取得のみを行い、サーバーの状態を変更しません。
POSTメソッド
- 用途: サーバーにデータを送信し、新しいリソースを作成する際に使用します。
- 例: フォームの送信、新規投稿の作成など。
- 特徴: リクエストボディにデータを含めて送信し、サーバーで新しいリソースを作成します。
PUTメソッド
- 用途: サーバー上の既存のリソースを新しいデータで置き換える際に使用します。
- 例: ユーザー情報の更新、ファイルの上書きなど。
- 特徴: 指定されたURIのリソースを完全に置き換えます。
DELETEメソッド
- 用途: サーバー上の特定のリソースを削除する際に使用します。
- 例: 投稿の削除、アカウントの削除など。
- 特徴: 指定されたURIのリソースを削除します。
PATCHメソッド
- 用途: サーバー上のリソースの一部を更新する際に使用します。
- 例: ユーザー情報の一部変更、設定の更新など。
- 特徴: リソースの一部を更新するため、PUTメソッドよりも効率的です。
HEADメソッド
- 用途: サーバーからリソースのヘッダー情報のみを取得する際に使用します。
- 例: リソースのメタ情報 (サイズや最終更新日時など) を取得する際。
- 特徴: レスポンスボディは含まれず、ヘッダー情報のみが返されます。
OPTIONSメソッド
- 用途: サーバーがサポートしているHTTPメソッドを確認する際に使用します。
- 例: サーバーがどのメソッドをサポートしているかを調べる際。
- 特徴: サーバーがサポートするメソッドを確認するために使用されます。
「GET」と「POST」の違い
HTTPメソッドの「GET」と「POST」は、Webブラウザとサーバー間でデータをやり取りする際に使用される主要な方法です。これらのメソッドは、それぞれ異なる目的と特徴を持っています。
GETメソッド
- 目的: サーバーからデータを取得するために使用されます。
- データの送信方法: データはURLの一部として送信されます。具体的には、URLの末尾に「?」を付け、その後に「キー=値」の形式でパラメータを追加します。
→ 例:
http://example.com/search?query=猫&sort=asc - 特徴:
- データの可視性: URLにデータが含まれるため、ブラウザのアドレスバーで確認できます。
- データの長さ制限: URLの長さに制限があるため、大量のデータの送信には適していません。
- キャッシュ: GETリクエストはキャッシュされることが多く、同じリクエストを繰り返すとキャッシュからデータが取得される場合があります。
- セキュリティ: パスワードや個人情報などの機密データをGETリクエストで送信するのは避けるべきです。
POSTメソッド
- 目的: サーバーにデータを送信し、新しいリソースの作成や既存のリソースの更新を行うために使用されます。
- データの送信方法: データはHTTPリクエストのボディ部分に含まれ、URLには表示されません。
→ 例: フォームに入力したデータがリクエストボディに含まれます。
- 特徴:
- データの可視性: データはURLに含まれないため、アドレスバーで確認することはできません。
- データの長さ制限: 理論的には、POSTメソッドは大量のデータを送信できますが、サーバーやブラウザによって制限が設けられている場合があります。
- キャッシュ: POSTリクエストは通常キャッシュされません。
- セキュリティ: データがURLに表示されないため、GETメソッドよりもセキュアに見えますが、通信が暗号化されていない場合、データは依然として盗聴される可能性があります。
まとめ
- GETメソッド: データの取得に使用され、データはURLに含まれます。
- POSTメソッド: データの送信やリソースの作成・更新に使用され、データはリクエストボディに含まれます。
これらのメソッドは、Webアプリケーションの設計において適切に使い分けることが重要です。例えば、検索機能などのデータ取得にはGETメソッドを、ユーザー登録やログインなどのデータ送信にはPOSTメソッドを使用します。
「GET」と「POST」の選択基準
使用目的
GETは主にデータの取得に使用され、リクエストがキャッシュ可能で、URLに表示されても問題がないデータに適しています。
POSTはデータの送信や新しいデータの作成、センシティブな情報の送信に適しています。
データ量
GETはURLの制約により、送信できるデータ量に制限があります。一方で、POSTはリクエストボディにデータを含めるため、比較的大きなデータを送信できます。
安全性
セキュリティ上の理由から、センシティブなデータの送信はPOSTが適しています。
ステータスコード
HTTPでは、サーバーがクライアントに返すレスポンスの結果を示すために、3桁のステータスコードが使用されます。ステータスコードはリクエストの成功、リダイレクト、クライアントエラー、サーバーエラーなど、様々な状態を表現します。
1xx (情報)
- 100 Continue
クライアントがリクエストを続行できることを示す。ヘッダーが受け入れられ、クライアントはボディを送信することが期待されます。
2xx (成功)
- 200 OK
リクエストが成功し、リクエストされた情報がレスポンスに含まれます。
3xx (リダイレクト)
- 301 Moved Permanently
リクエストされたリソースが新しい場所に永続的に移動します。ブラウザは次のリクエストから新しい場所を使用します。
- 302 Found (またはMoved Temporarily)
リクエストされたリソースが一時的に新しい場所に移動します。ブラウザは次のリクエストから新しい場所を使用します。
- 304 Not Found
リクエストされたコンテンツが未更新であることを通知します。Webブラウザに一次保存されたコンテンツが表示されます。
4xx (クライアントエラー)
- 400 Bad Request
クライアントのリクエストが不正であるため、サーバーがリクエストを理解できない場合表示されます。
- 401 Unauthorized
認証が必要なリソースに対して、クライアントが認証されていない場合表示されます。
- 403 Forbidden
クライアントがリソースにアクセスする権限がない場合表示されます。
- 404 Not Found
リクエストされたリソースが見つからない場合表示されます。
5xx (サーバーエラー)
- 500 Internal Server Error
サーバー内部でエラーが発生し、リクエストが処理できない場合表示されます。
- 502 Bad Gateway
ゲートウェイまたはプロキシサーバーが不正な応答を受け取り、サーバーがエラーを返した場合表示されます。
- 503 Service Unavailable
サーバーが一時的にダウンしているか、過負荷状態であるため、リクエストを処理できない場合表示されます。
これらは一般的なステータスコードの例であり、HTTPプロトコルには他にも多くのステータスコードが存在します。各ステータスコードは、通信の成功やエラーの詳細な状態をクライアントに伝えるために使われます。
メッセージヘッダー
HTTPメッセージヘッダーは、HTTPリクエストまたはレスポンス内の情報を伝達するためのメタデータの部分です。メッセージヘッダーを利用することでHTTPメッセージに関する詳細な情報を送信することが出来ます。
ヘッダーはキーと値のペアから構成され、通信の制御、認証、コンテンツの形式、クッキーなど、さまざまな目的で使用されます。
一般的ヘッダーフィールド
- Cache-Control: キャッシュの動作を指定します。
- Connection: リクエスト後はTCPコネクションを切断など接続状況に関する通知を示します。また、クライアントとサーバーの接続の管理方法を指定します。
- Date: HTTPメッセージが作成された日時を指定します。
- Upgrade: HTTPのバージョンをアップデートするように要求します。
- Cookie: クライアントからサーバーへのクッキーの送信やサーバーからのクッキーの受け取りに使用されます。
リクエストヘッダーフィールドの例
- Host: リクエスト先のサーバー名を指定します。
- Referer: 直前にリンクしていた (訪れていた) WebページのURLを指定します。
- User-Agent: ブラウザやクライアントの固有情報を提供します。(プロダクト名、バージョンなど)
- Accept: クライアントがサポートするメディアタイプを指定します。
レスポンスヘッダーフィールドの例
- Location: リダイレクト先のWebページ情報を指定します。
- Content-Type: レスポンスの本文のメディアタイプと文字エンコーディングを指定します。
- Content-Length: レスポンス本文の長さを指定します。
- Server: Webサーバーの種類やバージョンなどの情報を提供します。 (プロダクト名、バージョンなど)
エンティティヘッダーフィールド
- Allow: 利用可能なHTTPメソッドの一覧を指します。
- Content-Encoding: コンテンツのエンコード (データ変換) 方式を指します。
- Content-Language: コンテンツの使用言語を指します。
- Content-Length: コンテンツのサイズを指します。単位はバイト (byte)
- Content-Type: コンテンツの種類 (テキスト、画像) などを指します。
- Expires: コンテンツの有効期限を指します。
- Last-Modified: コンテンツの最終更新時刻
TCPによるデータ通信
Webサイトを閲覧する際、WebブラウザからのHTTPリクエストと、それに対するWebサーバーからのHTTPレスポンスが繰り返し行われます。これらのHTTPデータのやりとりを行うのは、主にTCPの役割です。
TCPは、コンピュータネットワークでのデータ通信において、信頼性の高いストリーム指向の通信を提供するプロトコルです。具体的には、クライアントとサーバーが通信可能な状態かを確認し、「コネクション」と呼ばれる通信経路を確立します。その後、データはクライアントとサーバー間で信頼性のあるストリームとして転送されます。データはシーケンス番号と確認応答番号を使用してセグメントに分割され、それぞれが相手に届いたかどうかが確認されます。
一方、HTTPはアプリケーション層のプロトコルであり、WebブラウザとWebサーバー間でのデータのやりとりを定義します。HTTPは、Webページの要求や送信を行うためのルールを提供しますが、実際のデータ転送の信頼性や順序の管理はTCPが担当します。このように、HTTPとTCPはそれぞれ異なる層で機能し、協力してWeb通信を実現しています。
このコネクションの確立は、次の3回のやりとりにより行われます。
- クライアントがサーバーに接続要求を送信 (SYN)
クライアントがサーバーに接続を要求するとき、クライアントは「SYNパケット」をサーバーに送信します。これは通常、TCPヘッダーの中でフラグフィールドの一部です。SYNパケットを受け取ったサーバーは、それに対して応答します。
- サーバーが接続要求を受信し、応答 (SYN-ACK) を返信
TCPでは信頼性のある通信を実現するために、データを送信した後、必ず送信相手からの確認応答を受け取ってデータの送信が完了したと判断します。この確認応答が「ACKパケット」です。
クライアントからの接続要求に対してサーバーがACKパケットを送信することで、接続可能であることを伝えます。また、サーバーはACKパケットを送信するのと同時に、サーバー自身の接続要求としてSYNフラグがセットされたSYNパケットを送信します。これを「SYN-ACKパケット」と言います。
- クライアントがサーバーの応答を確認 (ACK)
クライアントはサーバーからのSYN-ACKパケットを受信すると、これを確認するために「ACKパケット」をサーバーに返信します。これにより、双方向で通信可能なことを確認して、コネクションの確立が完了します。
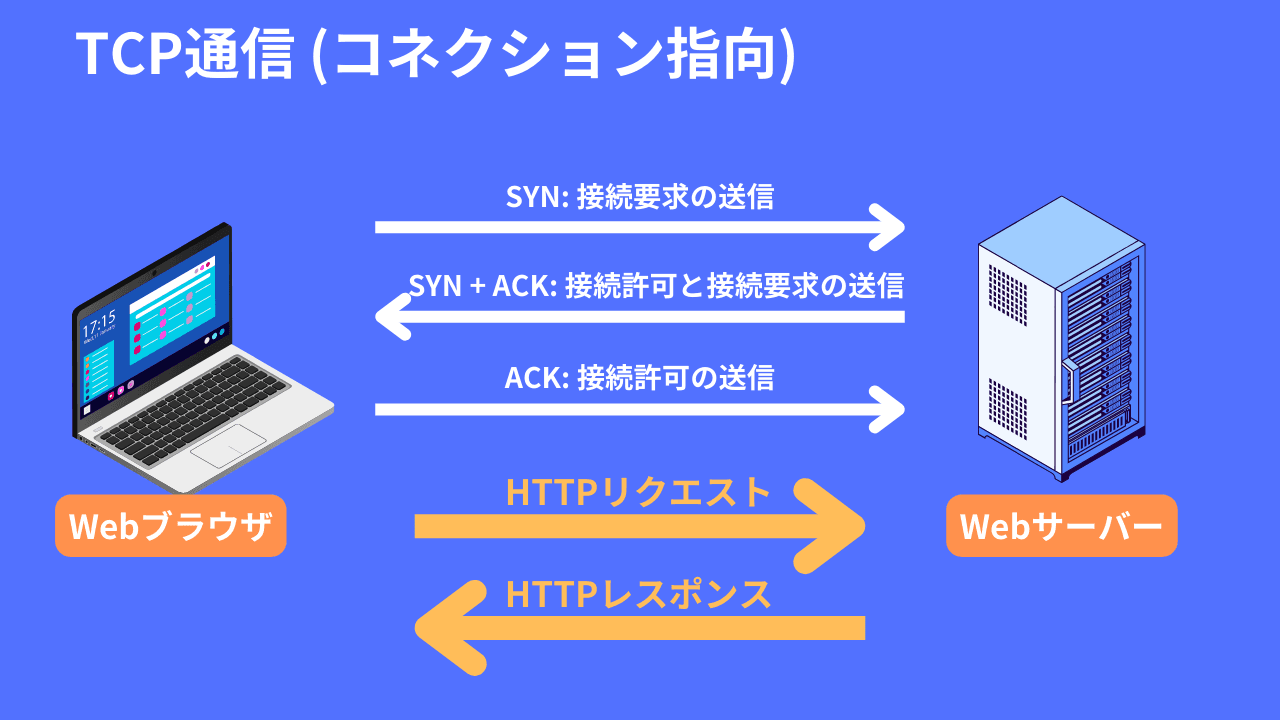
この手順は通常、「Three-Way Handshake」と呼ばれ、クライアントとサーバーの間で確実な通信の開始を保証します。この接続の確立後、クライアントとサーバーはデータの送受信を開始し、通信が終了するまでデータのやり取りが可能です。
HTTP / 1.1のやりとり
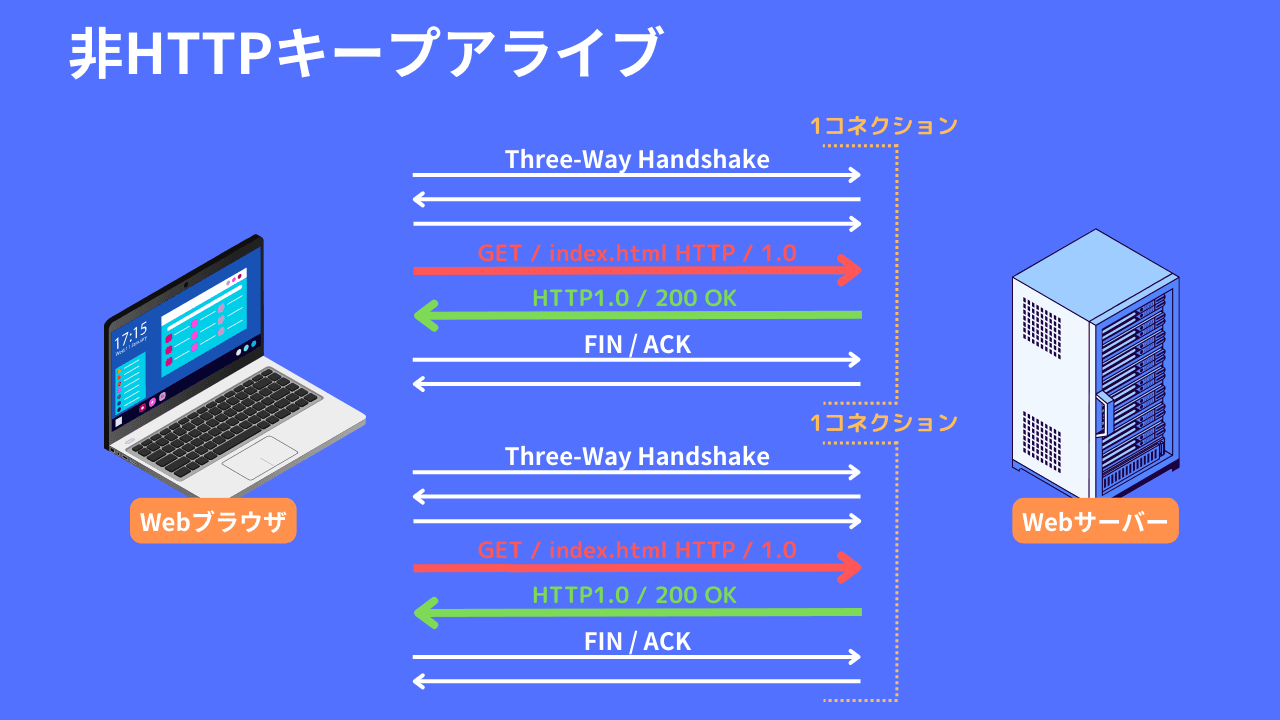
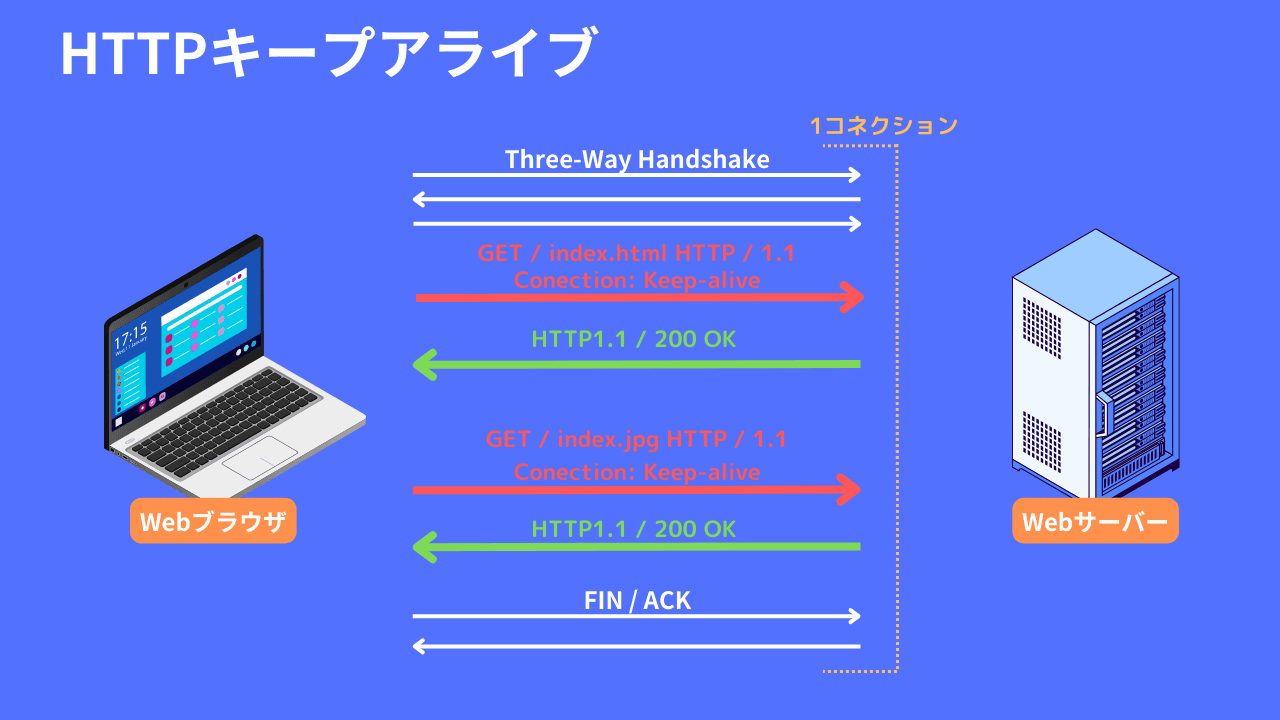
HTTPキープアライブとは
HTTPキープアライブ (HTTP Keep-Alive) は、HTTPプロトコルにおいて、単一のTCP接続を使用して複数のHTTPリクエストおよびレスポンスをやり取りする仕組みを指します。通常、クライアントがサーバーにリクエストを送信し、サーバーがレスポンスを返すと、接続が閉じられます。しかし、HTTPキープアライブを使用すると、同一のTCP接続を再利用して複数のリクエストやレスポンスを行うことができます。
HTTPパイプラインとは
HTTPパイプライン (HTTP Pipelining) は、HTTPプロトコルにおいて、複数のリクエストを一つのTCP接続で並行して送信し、サーバーからのレスポンスも同様に一つのTCP接続で非同期に受け取る仕組みです。通常、クライアントがサーバーに複数のリクエストを送信し、サーバーがその順序通りにレスポンスを返すまで待つ代わりに、HTTPパイプラインではリクエストが非同期に送信され、レスポンスも非同期に受信されます。
HTTPパイプラインの主な特徴と利点は以下の通りです。
- 並列処理
複数のリクエストを同時に送信できるため、通信の効率が向上します。これにより、通信の待ち時間が減少し、パフォーマンスが向上します。
- TCP接続の再利用
パイプラインが有効な接続では、同一のTCP接続を再利用して複数のリクエストおよびレスポンスを処理できるため、接続の確立や切断に伴うオーバーヘッドが減少します。
- リソースの効率的な利用
パイプラインを使用することで、サーバーとクライアントのリソースがより効率的に利用されます。
HTTP / 2のやりとり
ストリームとは
HTTP/2では、従来のHTTP/1.xの制約を克服するために「ストリーム」という概念が導入されました。これにより、1つのTCP接続上で複数のリクエストとレスポンスを同時に処理できるようになり、通信の効率性が大幅に向上しました。
具体的には、HTTP/2では「ストリーム」と呼ばれる仮想的な通信経路を使用して、複数のリクエストとレスポンスを並行して処理します。これにより、各リクエストとレスポンスが独立して処理されるため、1つのリクエストの処理に時間がかかっても、他のリクエストの処理が遅延することなく行われます。
このストリームの導入により、ウェブページの読み込み速度が向上し、ユーザー体験が改善されました。例えば、ウェブページに含まれる複数のリソース (画像、CSS、JavaScriptなど) を同時に効率よく取得できるようになりました。
また、HTTP/2ではデータの転送方法も改善され、ヘッダー圧縮やサーバープッシュなどの新機能が追加されました。これらの機能により、通信量の削減やリソースの事前送信が可能となり、さらにパフォーマンスが向上しました。
総じて、HTTP/2のストリーム機能は、ウェブ通信の効率性と速度を大幅に改善し、現代のウェブアプリケーションにおいて不可欠な技術となっています。
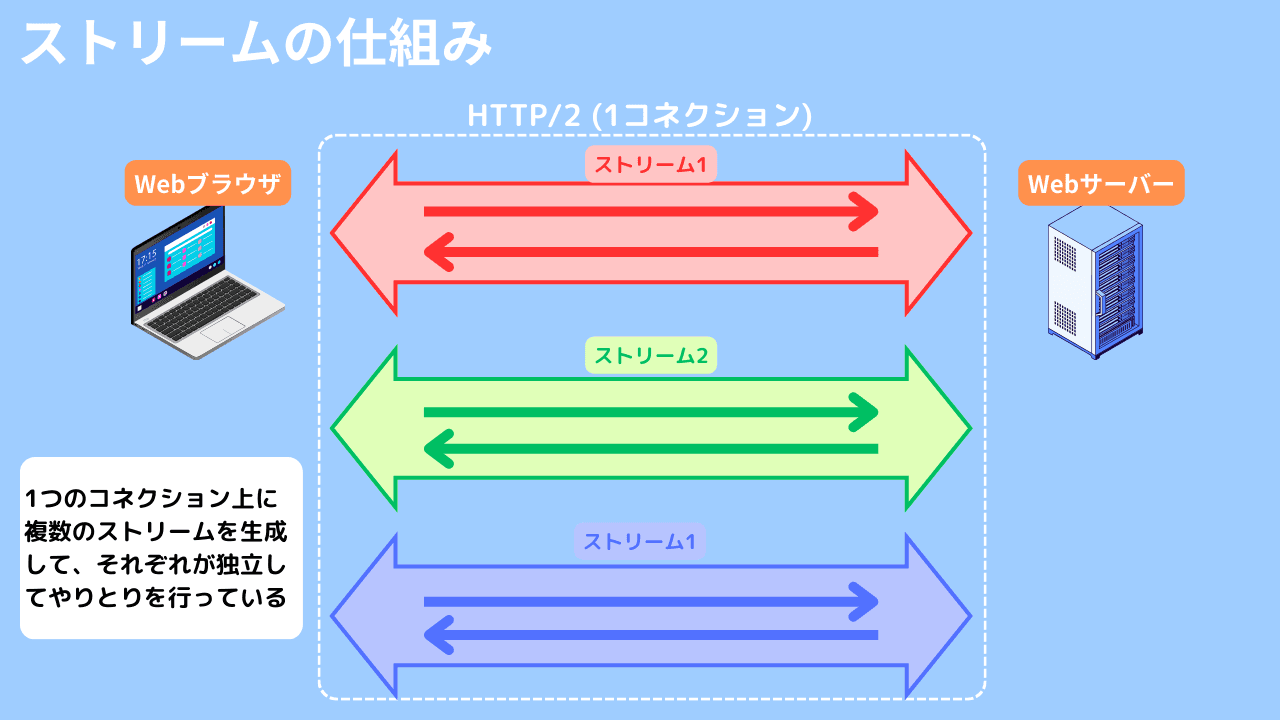

HTTPパイプラインとストリームは、どちらも複数リクエストを送信できることに変わりありません。しかし、HTTPパイプラインは順番通りにレスポンスする制約があるため、処理に時間がかかった際に待ち時間が発生します。
バイナリ形式の利用
バイナリ形式は、コンピュータがデータを表現するための形式の一つであり、テキスト形式とは対照的です。バイナリ形式では、データは0と1のビットの組み合わせで表現されます。
バイナリ形式を採用することで、変換処理にかかる時間と、ブラウザやサーバーへの負担を軽減できます。
データ表現
- バイナリ形式
データは2進数で表現され、コンピュータが直接理解できる形式です。バイナリ形式では、ビットやバイトなどが組み合わさって数値や文字、画像、音声などが表現されます。
- テキスト形式
データは通常、人間が読み書きしやすい形式で表現されます。ASCIIやUnicodeなどの文字コードを使用し、テキストエディタなどで直接編集できる形式です。
拡張性
- バイナリ形式
バイナリ形式は効率的であり、データをコンパクトに表現できるため、通常は効率的なデータ転送やストレージに向いています。しかし、人間が直接読み書きするのは難しいことがあります。
- テキスト形式
テキスト形式は人間が理解しやすい反面、データが増えると容量が大きくなりやすい傾向があります。
可読性
- バイナリ形式
直接的な意味がなく、一般の人が理解するのは難しいです。通常は専用のプログラムやツールが必要です。
- テキスト形式
人間が理解しやすく、エディタやテキスト処理ツールで簡単に編集できます。
用途
- バイナリ形式
画像、音声、ビデオ、実行可能ファイルなど、コンピュータが直接扱う多くのデータ形式がバイナリ形式で表現されます。
- テキスト形式
プログラムのソースコード、設定ファイル、文書、メッセージなど、人間が読み書きするデータがテキスト形式で表現されることが一般的です。
バイナリ形式は効率的であり、特に構造が複雑なデータを表現する際に重要ですが、可読性の点ではテキスト形式が優れていることがあります。どちらを使用するかは、データの性質や使用目的によります。
ヘッダーコンプレッション
HTTP/2では、ヘッダーの圧縮が導入されています。これにより、以前のHTTP/1.1では発生していたヘッダーの冗長な転送を削減し、通信効率を向上させます。ヘッダーは静的なもの (一般的によく使用されるヘッダー) と動的なもの (特定のストリームに関連するヘッダー) に分類され、適切に圧縮されます。
HTTP/2ではヘッダー情報の中から差分だけを送る「HPACK」と呼ばれる圧縮方式を利用することで、データ転送を削減できます。
サーバープッシュ
サーバープッシュは、HTTP/2プロトコルで導入された機能の一つであり、ウェブページのパフォーマンス向上を目的としています。通常、ウェブページはクライアント (ブラウザ) がリクエストを送信してサーバーが応答するというリクエスト-レスポンスモデルに基づいていますが、サーバープッシュではサーバーがクライアントに対して必要なリソースを積極的にプッシュすることができます。
サーバープッシュは、特にウェブページの初回読み込み時や、必要なリソースを予測してプッシュすることで通信の待ち時間を削減し、ページの読み込み速度を向上させることが期待されます。ただし、適切な使用が求められ、無駄なリソースをプッシュしてしまうことが逆効果になる可能性もあります。